テキストファイルに書き込む
FileOutputStreamクラス
プログラムからファイルへのStreamを扱います。
java.io.FileOutputStream

結論から申し上げますと、
このクラス単体ではちょっと使えない。
このクラス単体ではちょっと使えない。


えぇー!
でも、無いと困ります。
目次
1.継承関係
データをストリームとして利用する場合には、
Streamインターフェース(クラスの仲間)を実装したクラスを利用します。
FileOutputStreamも、Streamインターフェースを実装したクラスの仲間です。
特に、File に向けて Output する Stream を扱います。
Streamインターフェース(クラスの仲間)を実装したクラスを利用します。
FileOutputStreamも、Streamインターフェースを実装したクラスの仲間です。
特に、File に向けて Output する Stream を扱います。
Streamインターフェースを実装したクラスの継承関係
java.io.OutputStream 抽象クラス (java.io.Streamインターフェースを実装)
|
└ java.io.FileOutputStream クラス
重要
File に向けて Output する Stream を扱います。
2. コンストラクタ

出力先のファイルを指定するのに、
Fileクラスと Stringクラスの両方が使える。
追記したい場合は、第二引数を利用しよう。
Fileクラスと Stringクラスの両方が使える。
追記したい場合は、第二引数を利用しよう。
public FileOutputStream(String name)
throws FileNotFoundException
throws FileNotFoundException
public FileOutputStream(String name, boolean append)
throws FileNotFoundException
throws FileNotFoundException
public FileOutputStream(File file)
throws FileNotFoundException
throws FileNotFoundException
public FileOutputStream(File file, boolean append)
throws FileNotFoundException
throws FileNotFoundException
第一引数に指定されたファイルへの出力ストリームを作ります。
- ファイルが存在しない場合は作成されます。
- ファイルが存在した場合は上書きされます。(第二引数を参照ください)
- ファイルが存在していてもディレクトリであった場合は、FileNotFoundExceptionがスローされます。
- true なら既存のファイルの最後に追記されます。
- false なら既存のファイルを上書きします。
コンストラクタ 書式例
File file;
FileOutputStream outStream = new FileOutputStream(file);
FileOutputStream outStream = new FileOutputStream(file);
import java.io.FileOutputStream; が必要です。
例外処理を記述する場合には、以下をインポートする必要があります。
例外のimport
import FileNotFoundException;
3. writeメソッド
writeメソッドは、引数のバイト、又はバイト配列をこの出力ストリームに書き込みます。
public void write(int b)
throws IOException
throws IOException
writeメソッド 書式
FileOutputStream outStream;
int b;
outStream.write(b);
int b;
outStream.write(b);
例外処理を記述する場合には、以下をインポートする必要があります。
例外のimport
import IOException;
引数のバイトをこの出力ストリームに書き込みます。


引数は int なのに
「バイト」を書き込むんスか?
「バイト」を書き込むんスか?

そうなんだ。
int b って
たぶん byte の b なんだろうな。
実際には byte型の範囲でしか使えない。
int b って
たぶん byte の b なんだろうな。
実際には byte型の範囲でしか使えない。
ご参照↓
6.サンプルコード2
6.サンプルコード2


こっちは byte配列ね。
この方が使えるかな?
この方が使えるかな?

まあ
どちらかといえば。
どちらかといえば。
public void write(byte b[])
throws IOException
throws IOException
writeメソッド 書式
FileOutputStream outStream;
byte b[];
outStream.write(b[]);
byte b[];
outStream.write(b[]);
例外処理を記述する場合には、以下をインポートする必要があります。
例外のimport
import IOException;
引数のバイト配列をこの出力ストリームに書き込みます。
Point
byte型の範囲は、十進数で -128~127 ですが、
char型の範囲は、0~65535 です。
実際に使えるのは、範囲が重なっている 0~127 に限られます。
つまり書き込めるのは、ASCII文字だけですね。
char型の範囲は、0~65535 です。
実際に使えるのは、範囲が重なっている 0~127 に限られます。
つまり書き込めるのは、ASCII文字だけですね。
4. closeメソッド
書込みが終わったら必ず closeします。
ストリームを閉じて関連するシステム・リソースを解放します。
ストリームを閉じて関連するシステム・リソースを解放します。
public void close()
throws IOException
throws IOException
closeメソッド 書式
FileOutputStream outStream;
outStream.close();
outStream.close();
例外処理を記述する場合には、以下をインポートする必要があります。
例外のimport
import IOException;
5.サンプルコード1
それでは実際に使ってみましょう。
FileOutputStreamクラスのインスタンスを生成して、writeメソッドで書き込みます。
サンプルでは hello.txt というファイルに intの値を書き込んでいます。
hello.txt が存在しない場合には、自動的に作成してくれます。
FileOutputStreamクラスのインスタンスを生成して、writeメソッドで書き込みます。
サンプルでは hello.txt というファイルに intの値を書き込んでいます。
hello.txt が存在しない場合には、自動的に作成してくれます。
//Sample01_01.java import java.io.File; import java.io.FileOutputStream; import java.io.FileNotFoundException; import java.io.IOException; class Sample01_01{ public static void main(String[] args){ String path = "hello.txt"; File file = new File(path); try { FileOutputStream outStream = new FileOutputStream(file); int intCh = 'A'; outStream.write(intCh); outStream.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e){ e.printStackTrace(); } } }
コマンドライン
>cd ws ws>javac -encoding UTF-8 Sample01_01.java ws>java Sample01_01 ws>
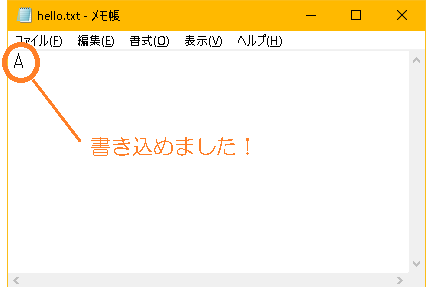


おお~!

まあ大体 ASCII文字 は
上手くいくもんだ。
上手くいくもんだ。
6.サンプルコード2
今度はひらがなを試してみましょう。
ひらがなは 1byte文字ではありません。
int (4byte)には収まりますが、byte(1byte)だとはみ出してしまいます。
ひらがなは 1byte文字ではありません。
int (4byte)には収まりますが、byte(1byte)だとはみ出してしまいます。
//Sample01_02.java import java.io.File; import java.io.FileOutputStream; import java.io.FileNotFoundException; import java.io.IOException; class Sample01_02{ /* NG例 意図した動作になりません。*/ public static void main(String[] args){ String path = "hello.txt"; File file = new File(path); try { FileOutputStream outStream = new FileOutputStream(file); int intCh = 'あ'; System.out.println(String.format("あ: %x", intCh)); outStream.write(intCh);//あ /*検証のため 8bitで桁溢れさせています。*/ byte byteData = (byte)intCh; System.out.println(String.format("(byte)あ: %x", byteData)); System.out.println((char)byteData);//B outStream.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e){ e.printStackTrace(); } } }
コマンドライン
>cd ws ws>javac -encoding UTF-8 Sample01_02.java ws>java Sample01_02 あ: 3042 (byte)あ: 42 B
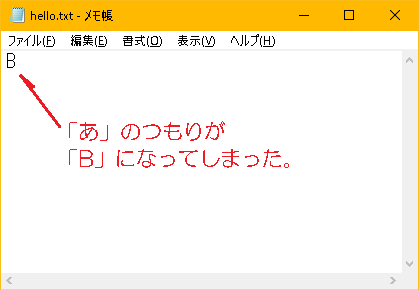
'あ' の文字コードは16進数で 0x3042 ですが、
先頭の 30 が溢れて 0x42 つまり 'B' になってしまいました。
引数のデータ型は intですが、実際に利用されるのは byte型の範囲だけです。
FileInputStream.read() の時にも、戻り値のデータ型は intでしたが、
実際に戻ってくるのは byte型(8bit)の範囲だけでしたね。
ご参照↓
「容赦なく1バイトにぶった切った」
先頭の 30 が溢れて 0x42 つまり 'B' になってしまいました。
引数のデータ型は intですが、実際に利用されるのは byte型の範囲だけです。
FileInputStream.read() の時にも、戻り値のデータ型は intでしたが、
実際に戻ってくるのは byte型(8bit)の範囲だけでしたね。
ご参照↓
「容赦なく1バイトにぶった切った」


はわわー。
使えね~っスね。
使えね~っスね。

7.サンプルコード3
今度は引数に byte配列を与えて試してみましょう。
ここでは ASCII文字限定で実行してみます。
'\n' は改行のエスケープシーケンスです。
ここでは ASCII文字限定で実行してみます。
'\n' は改行のエスケープシーケンスです。
//Sample01_03.java import java.io.File; import java.io.FileOutputStream; import java.io.FileNotFoundException; import java.io.IOException; class Sample01_03{ public static void main(String[] args){ String path = "hello.txt"; File file = new File(path); String inputText = "Hello!\nThis is Sample01_03!\n"; /*文字列を byte配列に無理やり変換*/ char[] charArray = inputText.toCharArray(); byte[] byteArray = new byte[charArray.length]; for(int i=0; i<charArray.length; i++){ byteArray[i] = (byte)charArray[i]; //注意:narrowing primitive↓ } try { FileOutputStream outStream = new FileOutputStream(file); outStream.write(byteArray); outStream.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e){ e.printStackTrace(); } } }
narrowing primitive = 狭くする基本データ型変換
ご参照↓
Java超入門
第七章 基本データ型の型変換
型変換の基本
3.明示的な型変換
桁あふれのリスクを承知で無理やりデータ型を変換しています。
ご参照↓
Java超入門
第七章 基本データ型の型変換
型変換の基本
3.明示的な型変換
桁あふれのリスクを承知で無理やりデータ型を変換しています。
コマンドライン
>cd ws ws>javac -encoding UTF-8 Sample01_03.java ws>java Sample01_03 ws>


やった~!
凄いじゃない!
凄いじゃない!

マヤ先輩。
今までのがひどかったから
すごくうまくいった気になってる
だけだと思いますよ?
今までのがひどかったから
すごくうまくいった気になってる
だけだと思いますよ?

ASCII文字限定で
エスケープシーケンス増し増しなら
上手くいくな。
エスケープシーケンス増し増しなら
上手くいくな。
8.まとめ
FileOutputStreamクラス単体では、多くの場合ニーズを満たせません。
FileOutputStreamクラスは、あくまでもストリーム(Stream)。
バイト配列を順番に書き込むのが役割分担です。
テキストを書き込むのであれば、ライター(Writer)と力を併せましょう。
FileOutputStreamクラスは、あくまでもストリーム(Stream)。
バイト配列を順番に書き込むのが役割分担です。
テキストを書き込むのであれば、ライター(Writer)と力を併せましょう。
お疲れ様でした。


© 2019 awasekagami